

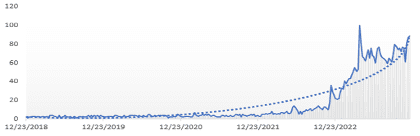
However, a gap still exists between the organizations successfully using AI and those struggling to make it work; as you can see in the Google Trends graph below, there is a significant increase in searches for “how to use AI” over the past two years – indicating there is still a market for people who aren’t using AI but would like to.
While these principals can be applied at the enterprise level across almost all verticals, this article focuses specifically on the financial services industry. Like all technology implementation roadmaps, when adopting AI within your organization, there are two main routes you can take:
- Leverage existing, off the shelf offerings, or
- Develop in-house for customized solutions
Given the size, complexity, and sensitivity of data in financial services, this industry lends itself to the latter of these two options for both immediate market differentiation and long-term reusability. As a specific and looming use case, the impactful shift in settlement cycle from two business days after the trade date (T+2) to one (T+1) (May 2024) merits interesting consideration for how AI, driven by a thoughtful data strategy, can be utilized to drive more straight-through-processing (STP) for the industry (something we will dive into further in our next article). While off the shelf solutions can yield early ROI, it’s crucial to develop a long-term, sustainable strategy for AI implementation.
In our work with clients, we’ve observed time and time again that an effective data strategy is the precursor to any data utilization strategy, including AI. Without it, you risk falling into the “garbage in, garbage out” trap.
In this article, we outline our proven approach to establishing a data foundation that unlocks lasting business value through AI. In a future piece, we will showcase some practical AI use cases to see quick ROI in the process of building that foundation.
The 5-step blueprint for building a data foundation for long-term AI success
Data architecture, governance and master data management are paramount to a successful enterprise-wide AI deployment. We advise our clients to follow the below five steps to get their centralized data warehouse in order before tackling advanced AI projects.
- Develop an enterprise-wide business data model: Many organizations grapple with disjointed systems due to legacy technology, past mergers and acquisitions, or siloed business units. If you’re a large enterprise, chances are your employees have been generating, collecting, and distributing data as part of their daily routines. An enterprise-wide data model is a comprehensive integration model covering all data within an organization. This visual representation defines and standardizes an entire enterprise’s data, providing a critical foundation for the subsequent steps.
- Select the right ETL tools: ETL, which stands for “Extract, Transform, and Load,” is pivotal in gathering, consolidating, and unifying/normalizing data from disparate systems. ETL can be complex, but it’s now an essential activity as organizations strive to harness their data’s potential. Cloud-based data integration platforms like Fivetran, Matillion and Keboola can simplify data extraction, loading, and transformation processes, making them more automated and reliable. We explore the pros and cons of each in detail in this article.
- Transform data to align with your data model: Preparing data for AI requires several steps, which we outline fully in this article, including data cleansing to ensure data integrity, and data transformation to convert clean data into a suitable format for analysis. It’s also crucial to collect the right volume and type of data while managing data quality to mitigate risks, making dimensionality reduction essential to improve AI performance. Finally, we recommend taking a deliberate strategy when splitting your clean data between training and testing sets to have representative samples of your target populations and to avoid over/underfitting your AI models. Discussing further details of this stage go beyond the scope of this article, but it is something all tech leaders should consider as part of their data processing.
- Select the right tools for data warehousing: A data warehouse serves as a centralized hub for collecting, storing, and managing data from various business sources, supporting business intelligence activities. Leading solutions like Databricks and Snowflake offer data warehousing (and data lakehouse) capabilities, helping companies efficiently store, process, and utilize their data – read more about their 2023 conferences in our recent article.
- Master long-term data management, hygiene, and governance: As you establish your data foundation, maintaining effective data management, hygiene, and governance is critical. We recommend setting up a data center of excellence (CoE) for pipeline automation, monitoring, lifecycle management, and governance. Your CoE should serve as a shared knowledge hub, preventing silos across business units and maximizing ROI.
By following these five steps, organizations can appreciate the significance of a long-term data strategy and set the stage for successful AI implementation. Taking a financial services lens, we’ll discuss a few key AI use cases in our final article of this three-part AI series to highlight powerful benefits this technology can offer with the right data foundation.




